
JDK 설정하는 여러 방법부터 도메인에 대한 설명 그리고 실제 코드레벨에서 적용까지 상세하게 설명해주셔서 좋았습니다. 클린코드를 적용하기 위해 테스트코드를 어떻게 작성할 수 있는지, 도메인 모델 아키텍처와 헥사고날의 사실과 오해에 대한 내용까지 깊이 있게 학습할 수 있습니다
개발환경구성
자바 버전 관리
- IDE의 JDK 다운로드
- JDK 배포판 웹사이트에서 다운로드
- JDK 버전을 관리하는 도구 이용
- 대표적으로 SDKMAN 사용
- 여러 Java / 개발 SDK 버전을 프로젝트별로 깔끔하게 관리해주는 도구
- 프로젝트 루트내에 관리할 수 있어서 git에 올려서 같이 공유할 수 있음
API 테스트
- Postman
- HTTPie
- 터미널을 사용한 간단하고 빠른 테스트 가능
Docker Compose
- Spring Boot 3.1버전부터 Docker Compose support 사용 지원
- intellij에서 편리하게 Docker Compose를 설정하고 사용할 수 있다.
- 실행시 반드시 도커 데몬 running 상태
- 설정 변경시 도커 down 후에 다시 앱 실행
도메인
- 사용자가 프로그램, 또는 소프트웨어 서비스를 적용하는 주제 영역을 도메인이라고 한다.
- 모든 소프트웨어를 도메인이라고도 볼 수 있다.
- 도메인은 현실 세계의 일부이고, 단순히 코드로 직접 옮길 수 없다. 따라서 도메인의 추상화인 도메인 모델을 만들어야 한다.
- 도메인 모델은 소프트웨어가 해결하려는 특정 문제 영역(도메인)의 핵심지도이다.
도메인 주도 설계 (DDD)
- 변경사항이 많은 도메인의 복잡성이 주는 문제를 해결하기 위해 나온 설계법이다.
- 도메인 모델을 중심으로 개발한다.
- 팀 안에서 도메인 모델에 기반한 단일 어휘체계를 만들고 이를 문서, 회의, 대화 그리고 코드까지 일관되게 사용한다. (보편 언어 - 유비쿼터스)
도메인 모델 만들기
- 도메인 전문가(실무자)에게 듣고 배우기
- ‘중요한 것’들 찾기 (개념 식별)
- ‘연결 고리’ 찾기 (관계 정의)
- ‘것’들을 설명하기 (속성 및 기본 행위 명시)
- 그려보기 (시각화) -> 클래스 다이어그램, 개념 도식화(격벽을 사용한 개념도)
- 토론하고 다듬기 (반복)
엔티티
- 도메인 안에 있는 대상이나 개념
- 고유한 식별자(identity)를 가지고 이를 통해서 개별적으로 구분된다.
- 생명주기를 가진다. 시간의 흐름에 따라 상태가 변경될 수 있다.
도메인 모델 패턴
- 도메인/비즈니스 로직을 구성하는 아키텍처 패턴의 한가지
- 도메인 모델의 속성과 행위를 모두 포함하는 도메인의 오브젝트 모델이다.
- 다른 방법인 트랜잭션 스크립트는 하나의 업무절차(TX)를 처리하기 위한 스크립트(메서드)를 만들고 비즈니스 로직을 순서대로 코드로 작성하는 방법이다.
도메인 서비스
- 도메인 안에서 구현하기 애매한 기술적인 요소가 들어간 경우 도메인 서비스(Domain Service)를 사용한다.
- 인터페이스를 만들어 메서드(행위)로만 관리하도록 한다.
- 스프링의
@Service를 사용한 영역과는 다른 영역이다. - 외부에서 도메인 서비스를 주입하는 경우 생성자를 사용하는 것보다는
static을 사용한 정적 팩토리 메서드가 더 유용하다.
private Member() {
}
public static Member create(MemberCreateRequest createRequest, PasswordEncoder passwordEncoder) {
Member member = new Member();
member.email = Objects.requireNonNull(createRequest.email());
member.nickname = Objects.requireNonNull(createRequest.nickname());
member.passwordHash = Objects.requireNonNull(passwordEncoder.encode(createRequest.password()));
member.status = MemberStatus.PENDING;
return member;
}
값 객체(Value Object)
- 도메인 모델에서 식별자가 필요하지 않고 속성/값으로만 구별되는 오브젝트
- 엔티티가 너무 많은 책임을 가지는 것을 방지
- 불변 객체이므로, 생성 이후에 상태가 변하지 않고 변경이 필요하면 새로운 객체로 교체한다.
- 값 객체에서 동등성 비교를 하기 위해서 반드시
equals와hashCode를 재구현해야 한다. - record를 사용한다면 record 클래스가 대신 이를 구현해준다.
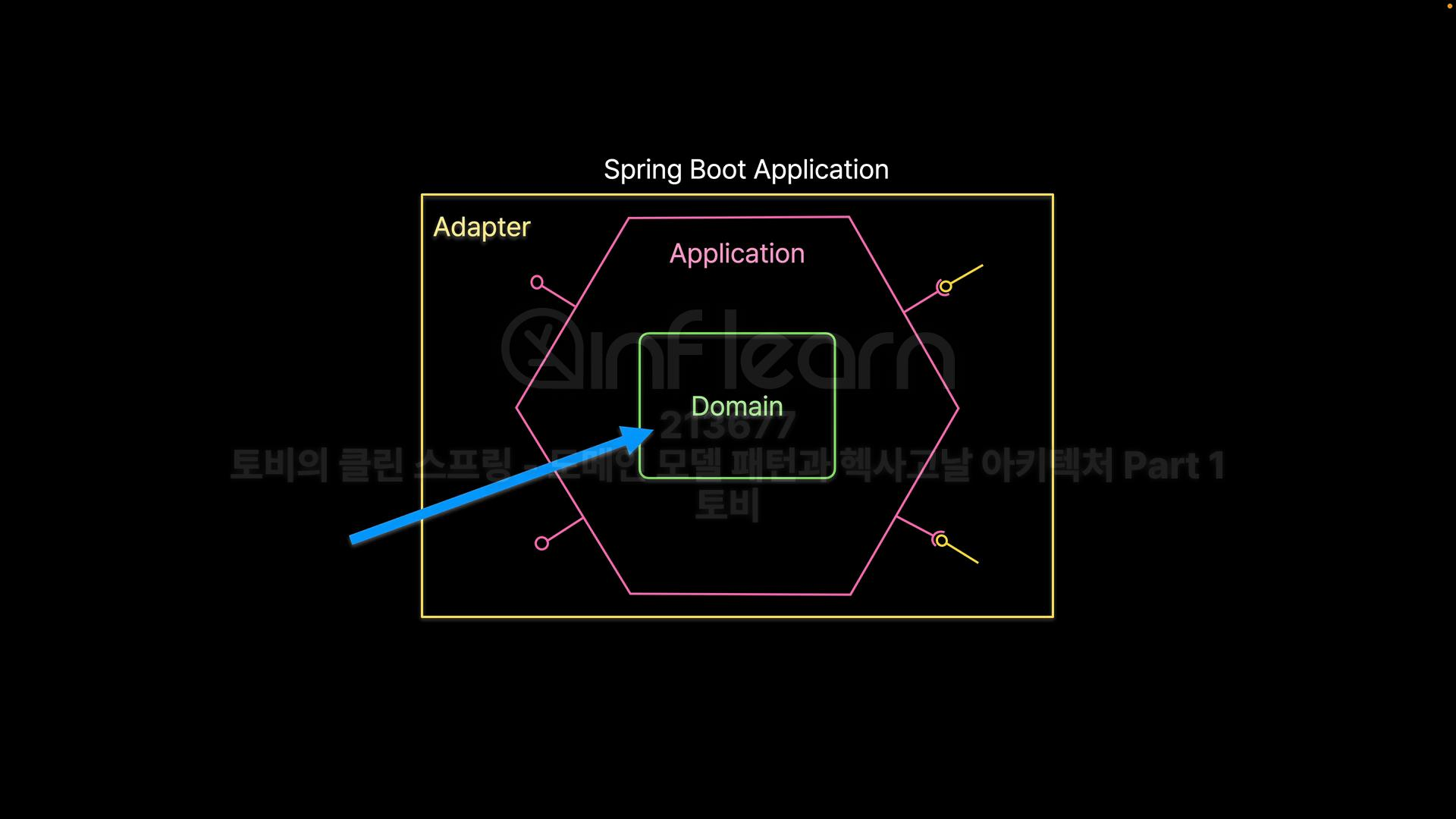
헥사고날 아키텍처
- 계층형 아키텍처의 단방형 비대칭 구조가 아닌 대칭형(symmetric) 아키텍처
- 위 아래, 좌 우가 아닌 애플리케이션의 내부와 외부 세계라는 대칭 구조를 가진다.
- 그리기 쉬운 대표적인 도형인 육각형(hexagonal)으로 설명
4 계층 아키텍처
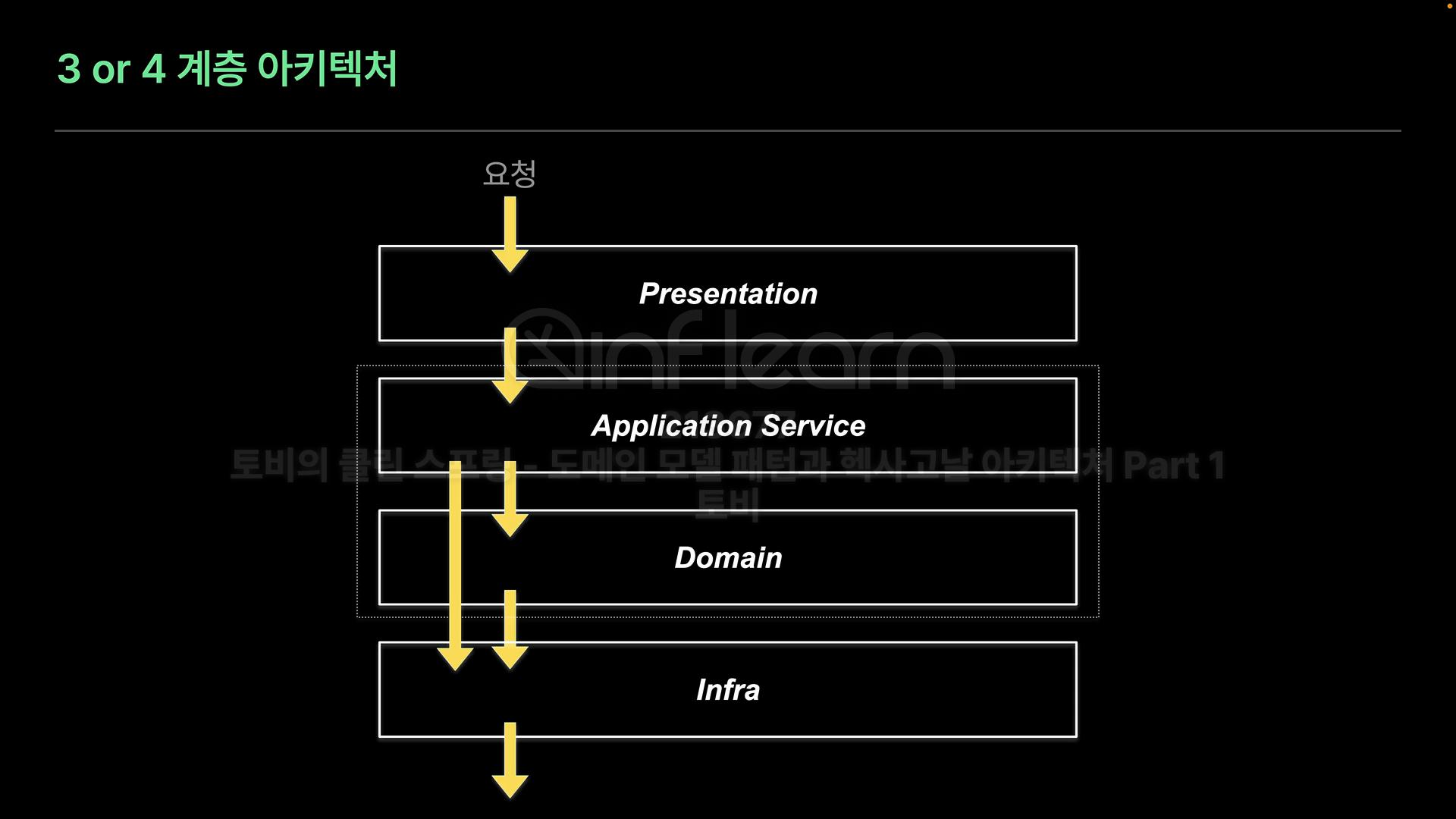
- 도메인 주도 개발(DDD)
- 결국 도메인 주도 개발 패턴을 지킨 아키텍처가 헥사고날 아키텍처가 된다.
특징과 장점
- 테스팅 - 운영 시스템에 연결되지 않고 애플리케이션 테스트
- 애플리케이션과 상호작용하는 액터(Actor)가 바뀌더라도 다시 빌드하지 않고 테스트
- 기술정보가 도메인 로직 안으로 노출되지 않도록 보호한다.
- 컴포넌트를 각각 개발하고 연결하는 방식으로 큰 시스템을 분리할 수 있다. (MSA)
- 외부 연결을 다른 것으로 변경할 수 있다.
- 의존된 기술 요소를 제거하여 도메인 설계에 집중한다.
포트와 어댑터 아키텍처
- 도메인(핵심 로직)을 중심에 두고, 외부 시스템(DB, UI, API 등)은 전부 교체 가능한 어댑터로 만든다
- Domain: 순수 비즈니스 로직
- Port: 도메인이 외부와 소통하는 인터페이스
- 포트는 도메인 안에 존재
- 기술(DB, HTTP, Kafka 등)을 전혀 모름
- Adapter: Port를 구현해서 실제 기술과 연결
- 어댑터는 도메인 바깥에 있음
- 기술 의존 코드 포함 가능
정리
- 외부에서 내부로 향하는 일종의 계층 구조
- 코드의 의존 방향은 내부로만 향한다
- 어댑터 -> 애플리케이션 -> 도메인
- 반대는 절대로 안된다
- 단, 사용의 흐름은 비대칭적이다.
- 헥사고날 아키텍처의 핵심은 테스트코드를 작성하는 것
- CQS(Command Query Seperate) 패턴 적용
MemberFinder,MemberRegister인터페이스 분리
JPA 모델과 도메인 모델
- 도메인 모델은 DB와 매핑되는 데이터 모델과 다르며 이를 분리해야 한다.
- Ex1)
Member,MemberEntity분리하여 관리 - Ex2)
MemberRepository,MemberRepositoryJpaAdapter
- Ex1)
- 레거시 DB가 너무 오래된 경우 데이터 모델과 도메인 모델이 너무 다르기 때문에 분리하는 것이 좋다.
- 도메인 모델 설계가 안정적이면 그 이후에 데이터 마이그레이션 진행
- JPA가 아닌 NoSQL 등 데이터 저장 기술이 바뀌는 경우에 유연하다.
- 다만, 데이터 자장 기술이 바뀌는 경우가 거의(?) 없을 것이다
분리하지 않아도 되는 경우
- 도메인 모델과 데이터 모델이 거의(?) 동일한 경우
- 도메인 코드에 JPA 애노테이션은 기술 의존적이므로 분리해야 한다.
- JPA 애노테이션이 붙었다고 기술에 의존적일까?
- 도메인 모델과 데이터 모델이 동일한 상태에서 JPA가 아닌 다른 기술을 쓴다해도 충분히 대체 가능
- 애노테이션은 단순 주석일뿐.
- 클래스의 증가는 복잡성을 증가시킨다
- JPA 기술의 정체성
- JPA의 엔티티는 경량 영속 도메인 오브젝트
중요한 것은 팀의 컨벤션을 따르는 것이다. 정답은 없다. 새로 들어온 내가 “도메인 모델과 데이터 모델을 분리해야 한다고 배웠으니까 이렇게 사용해” 라고 강요하는건 바보짓이다. 팀이 이미 안정적으로 사용하고 있는 컨벤션이 있다면 따르는 것이고, 서비스 안정화 하는 것이 먼저다. 다만, 추후 안정된 후에 의견을 제시할 수는 있을 것이다.
- 그럼에도 JPA 관련 애노테이션이 덕지덕지 붙어있어서 순수 도메인 코드를 보기가 힘들 수도 있다. (그래서 분리하려는 경향이 있다)
orm.xml파일을 만들어서 관리하는 방법으로 해결할 수 있다.- 그러면 기존 JPA 엔티티의 애노테이션들을 모두 제거할 수 있다.
@Id가 붙은 컬럼을 슈퍼클래스로 만드는 경우 반드시equals와hashCode를 재구현해야 한다.- 클래스에
@MappedSuperclass추가 필요
- 클래스에
애그리거트
Member:MemberDetail-> 1:1 관계- 각각 엔티티에 대해 각각의 Repository로 분리하여 관리하므로 복잡성이 증가한다
Member와MemberDetail는 매우 밀접한 관계이므로 하나의 그룹으로 만든 것을 Member Aggregate, 애그리거트라고 한다.Member: Aggregate RootMemberDetail: Aggregate Member
- Member Aggregate를 가지고 하나의 Repository로 관리한다
- 정의: 데이터 변경의 목적을 위해 하나의 단위로 취급되는 연관된 객체들의 클러스터
애그리거트 적용 방법
- JPA의 cascading을 적절하게 활용
- Repository는 애그리거트 단위
Repository<T, ID> : T = Aggregate Root
- 다른 애그리거트의 참조는 Aggregate Root를 통해서만 한다
- 성능에 부담을 주기 때문에
lazy loading활용 필요 - 정답은 없다
Entity vs DTO
애플리케이션 포트의 리턴 타입은?
- DTO를 리턴하는 방식의 가장 큰 문제는 프레젠테이션 로직이 애플리케이션 레이어로 침투하는 것이다
- 뷰(view) 로직에 따라 엔티티에서 복제되는 DTO의 구성이 달라진다
- DTO를 통해 애플리케이션 계층이 어댑터 계층의 로직에 의존한다
- 이는 완화된 아키텍처를 깨는 행위이다
- 다만, 복잡한 리포트성 조회 결과는 DTO를 리턴한다
따라서 애플리케이션(서비스) 계층의 리턴타입은 가능하다면 엔티티로 한다 - 애그리거트 루트 활용
]]>







